Afin de répondre aux besoins des services cloud, le réseau se divise progressivement en deux couches : l'infrastructure sous-jacente et l'infrastructure de superposition. L'infrastructure sous-jacente correspond aux équipements physiques (routeurs, commutateurs, etc.) des centres de données traditionnels. Elle privilégie la stabilité et assure une transmission de données fiable. L'infrastructure de superposition, quant à elle, encapsule le réseau métier au-dessus de l'infrastructure sous-jacente, le rapprochant ainsi du service. Grâce à l'encapsulation via les protocoles VXLAN ou GRE, elle offre aux utilisateurs des services réseau conviviaux. Ces deux infrastructures sont à la fois liées et indépendantes ; elles peuvent évoluer indépendamment l'une de l'autre.
Le réseau sous-jacent constitue la base du réseau. En cas d'instabilité de ce réseau, l'activité ne peut être assurée par un SLA. Après les architectures réseau à trois couches et Fat-Tree, l'architecture réseau des centres de données évolue vers l'architecture Spine-Leaf, marquant ainsi la troisième application du modèle de réseau CLOS.
Architecture de réseau de centre de données traditionnelle
Conception à trois couches
De 2004 à 2007, l'architecture réseau à trois niveaux était très répandue dans les centres de données. Elle comprend trois couches : la couche cœur (l'épine dorsale du réseau, assurant la commutation à haut débit), la couche d'agrégation (qui fournit une connectivité basée sur des politiques) et la couche d'accès (qui connecte les postes de travail au réseau). Le modèle est le suivant :
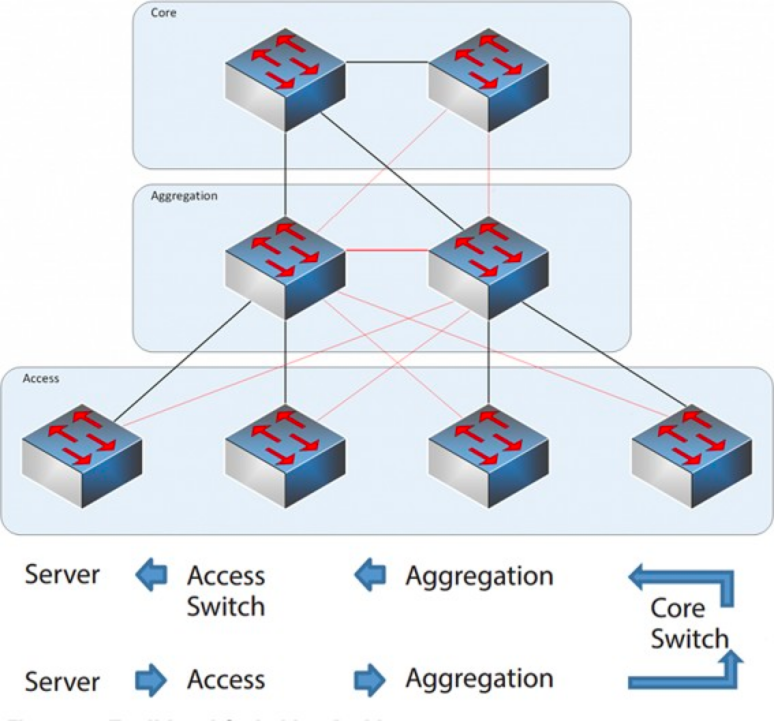
Architecture réseau à trois couches
Couche centrale : Les commutateurs centraux assurent le transfert à haut débit des paquets entrant et sortant du centre de données, la connectivité aux multiples couches d'agrégation et un réseau de routage L3 résilient qui dessert généralement l'ensemble du réseau.
Couche d'agrégation : Le commutateur d'agrégation se connecte au commutateur d'accès et fournit d'autres services, tels que pare-feu, déchargement SSL, détection d'intrusion, analyse de réseau, etc.
Couche d'accès : Les commutateurs d'accès se trouvent généralement en haut de la baie, ils sont donc également appelés commutateurs ToR (Top of Rack), et ils se connectent physiquement aux serveurs.
En général, le commutateur d'agrégation marque la démarcation entre les réseaux de couche 2 (L2) et de couche 3 (L3) : le réseau L2 se situe en aval du commutateur d'agrégation, et le réseau L3 au-dessus. Chaque groupe de commutateurs d'agrégation gère un point de livraison (POD), et chaque POD constitue un réseau VLAN indépendant.
Protocole de boucle réseau et d'arbre couvrant
La formation de boucles est principalement due à la confusion engendrée par des chemins de destination imprécis. Lors de la construction de réseaux, les utilisateurs, soucieux de garantir la fiabilité, emploient généralement des équipements et des liaisons redondants, ce qui entraîne inévitablement la formation de boucles. Le réseau de couche 2 se trouvant dans le même domaine de diffusion, les paquets de diffusion sont transmis de manière répétée dans la boucle, provoquant une tempête de diffusion susceptible d'entraîner instantanément le blocage des ports et la paralysie des équipements. Par conséquent, pour prévenir les tempêtes de diffusion, il est essentiel d'empêcher la formation de boucles.
Pour éviter la formation de boucles et garantir la fiabilité du réseau, il est nécessaire de transformer les dispositifs et liaisons redondants en dispositifs et liaisons de secours. Autrement dit, les ports et liaisons des dispositifs redondants sont bloqués en temps normal et ne participent pas au transfert des paquets de données. Ce n'est qu'en cas de défaillance du dispositif, port ou liaison de transfert principal, entraînant une congestion du réseau, que les ports et liaisons des dispositifs redondants sont activés afin de rétablir le fonctionnement normal du réseau. Ce contrôle automatique est assuré par le protocole STP (Spanning Tree Protocol).
Le protocole STP (Spanning Tree Protocol) fonctionne entre la couche d'accès et la couche de destination. Son cœur est un algorithme d'arbre couvrant exécuté sur chaque pont compatible STP. Cet algorithme est spécifiquement conçu pour éviter les boucles de pontage en présence de chemins redondants. STP sélectionne le meilleur chemin de données pour l'acheminement des messages et bloque les liens qui ne font pas partie de l'arbre couvrant, ne laissant ainsi qu'un seul chemin actif entre deux nœuds du réseau ; l'autre liaison montante est bloquée.
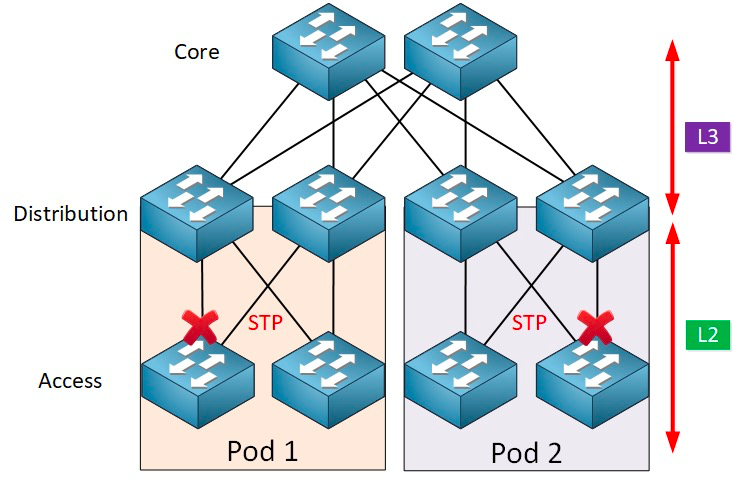
Le protocole STP présente de nombreux avantages : il est simple, prêt à l’emploi et ne nécessite que très peu de configuration. Les machines de chaque pod appartiennent au même VLAN, ce qui permet au serveur de modifier son emplacement arbitrairement au sein du pod sans changer l’adresse IP ni la passerelle.
Cependant, le protocole STP ne peut pas utiliser de chemins de transfert parallèles et désactive systématiquement les chemins redondants au sein du VLAN. Inconvénients du protocole STP :
1. Convergence lente de la topologie. Lorsque la topologie du réseau change, le protocole Spanning Tree prend 50 à 52 secondes pour achever la convergence de la topologie.
2. Il ne peut pas assurer la fonction d'équilibrage de charge. En cas de boucle dans le réseau, le protocole Spanning Tree se contente de bloquer cette boucle, empêchant ainsi la transmission des paquets de données et gaspillant les ressources réseau.
Défis liés à la virtualisation et au trafic Est-Ouest
Après 2010, afin d'améliorer l'utilisation des ressources de calcul et de stockage, les centres de données ont commencé à adopter la virtualisation, et un grand nombre de machines virtuelles ont fait leur apparition sur le réseau. La virtualisation transforme un serveur en plusieurs serveurs logiques ; chaque machine virtuelle peut fonctionner indépendamment, possède son propre système d'exploitation, ses applications, ainsi que ses propres adresses MAC et IP, et se connecte à l'infrastructure externe via un commutateur virtuel (vSwitch) interne au serveur.
La virtualisation s'accompagne d'une exigence essentielle : la migration à chaud des machines virtuelles. Il s'agit de la possibilité de déplacer un système de machines virtuelles d'un serveur physique à un autre tout en maintenant le fonctionnement normal des services sur les machines virtuelles. Ce processus est transparent pour les utilisateurs finaux ; les administrateurs peuvent ainsi allouer les ressources serveur avec flexibilité, ou réparer et mettre à niveau les serveurs physiques sans perturber l'utilisation normale des systèmes.
Afin de garantir la continuité du service pendant la migration, il est impératif que non seulement l'adresse IP de la machine virtuelle reste inchangée, mais aussi que son état d'exécution (notamment l'état de la session TCP) soit préservé. Par conséquent, la migration dynamique de la machine virtuelle ne peut être effectuée qu'au sein du même domaine de couche 2, et non entre domaines de couche 2 différents. Ceci implique la nécessité de domaines de couche 2 plus étendus, de la couche d'accès à la couche cœur.
Dans l'architecture traditionnelle des grands réseaux de couche 2, la frontière entre les couches 2 et 3 se situe au niveau du commutateur central. Le centre de données situé sous ce commutateur constitue un domaine de diffusion complet, c'est-à-dire le réseau de couche 2. Cette configuration permet un déploiement flexible des équipements et une migration aisée, sans nécessiter de modification de la configuration IP et des passerelles. Les différents réseaux de couche 2 (VLAN) sont acheminés via les commutateurs centraux. Cependant, cette architecture exige du commutateur central la gestion de tables MAC et ARP volumineuses, ce qui impose des contraintes importantes sur ses capacités. De plus, le commutateur d'accès (TOR) limite également l'envergure du réseau. Ces limitations finissent par restreindre la capacité d'extension et d'élasticité du réseau, et engendrent des problèmes de latence au niveau de la planification des trois couches, ce qui ne permet pas de répondre aux besoins futurs des entreprises.
Par ailleurs, le trafic est-ouest généré par la virtualisation pose également des défis au réseau traditionnel à trois couches. Le trafic des centres de données peut être globalement divisé en plusieurs catégories :
Circulation nord-sud :Trafic entre les clients situés en dehors du centre de données et le serveur du centre de données, ou trafic du serveur du centre de données vers Internet.
Circulation est-ouest :Le trafic entre les serveurs d'un même centre de données, ainsi que le trafic entre différents centres de données, comme la reprise après sinistre entre centres de données, la communication entre les clouds privés et publics.
L'introduction de la technologie de virtualisation rend le déploiement des applications de plus en plus distribué, et l'« effet secondaire » est l'augmentation du trafic est-ouest.
Les architectures traditionnelles à trois niveaux sont généralement conçues pour un trafic nord-sud.Bien qu'il puisse être utilisé pour le trafic est-ouest, il se peut qu'il ne fonctionne pas comme prévu.
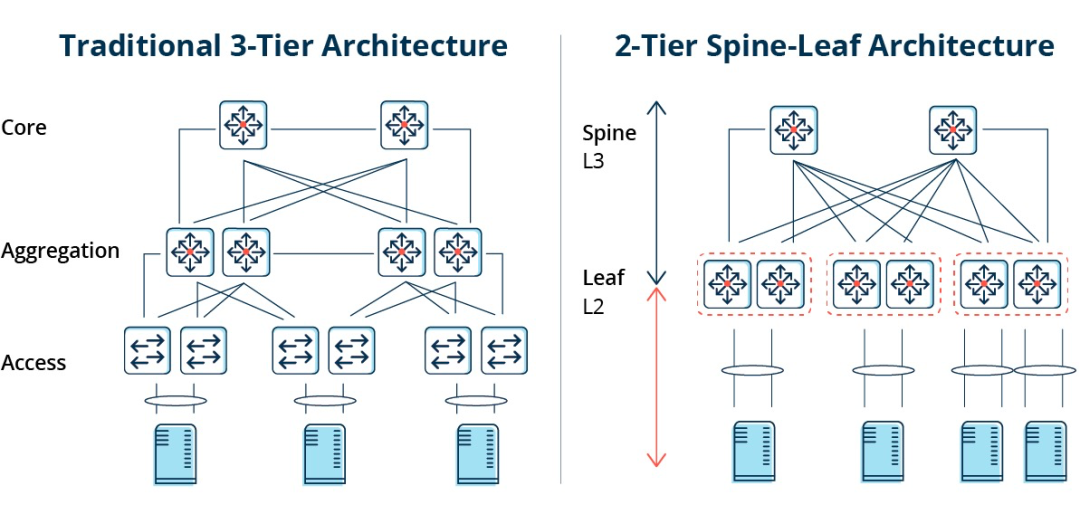
Architecture traditionnelle à trois niveaux contre architecture en colonne vertébrale et en feuilles
Dans une architecture à trois niveaux, le trafic est-ouest doit transiter par des équipements des couches d'agrégation et de cœur de réseau, ce qui implique un passage inutile par de nombreux nœuds. (Serveur → Accès → Agrégation → Commutateur cœur de réseau → Agrégation → Commutateur d'accès → Serveur)
Par conséquent, si un volume important de trafic est-ouest transite par une architecture réseau traditionnelle à trois niveaux, les périphériques connectés au même port de commutateur peuvent se disputer la bande passante, ce qui entraîne de mauvais temps de réponse pour les utilisateurs finaux.
Inconvénients de l'architecture réseau traditionnelle à trois couches
On constate que l'architecture réseau traditionnelle à trois couches présente de nombreuses lacunes :
Gaspillage de bande passante :Pour éviter les boucles, le protocole STP est généralement exécuté entre la couche d'agrégation et la couche d'accès, de sorte qu'une seule liaison montante du commutateur d'accès transporte réellement le trafic, les autres liaisons montantes étant bloquées, ce qui entraîne un gaspillage de bande passante.
Difficultés liées au déploiement de réseaux à grande échelle :Avec l'expansion des réseaux, les centres de données sont répartis dans différentes zones géographiques, les machines virtuelles doivent être créées et migrées n'importe où, et leurs attributs réseau tels que les adresses IP et les passerelles restent inchangés, ce qui nécessite la prise en charge d'une couche 2 robuste. Dans la structure traditionnelle, aucune migration n'est possible.
Absence de trafic est-ouest :L'architecture réseau à trois niveaux est principalement conçue pour le trafic nord-sud. Bien qu'elle prenne également en charge le trafic est-ouest, ses limitations sont évidentes. En cas de trafic est-ouest important, la pression sur les commutateurs des couches d'agrégation et cœur de réseau augmente considérablement, limitant ainsi la taille et les performances de ces couches.
Cela place les entreprises face au dilemme du coût et de l'évolutivité :La prise en charge de réseaux haute performance à grande échelle exige un grand nombre d'équipements de couche de convergence et de couche cœur, ce qui engendre des coûts élevés pour les entreprises et impose une planification préalable du réseau. Un réseau de petite taille entraîne un gaspillage de ressources, tandis qu'une expansion continue complexifie son intégration.
L'architecture du réseau épine-feuille
Qu'est-ce que l'architecture réseau Spine-Leaf ?
En réponse aux problèmes susmentionnés,Une nouvelle conception de centre de données, l'architecture réseau Spine-Leaf, a émergé ; c'est ce que nous appelons un réseau Leaf Ridge.
Comme son nom l'indique, l'architecture comporte une couche Spine et une couche Leaf, comprenant des commutateurs Spine et des commutateurs Leaf.
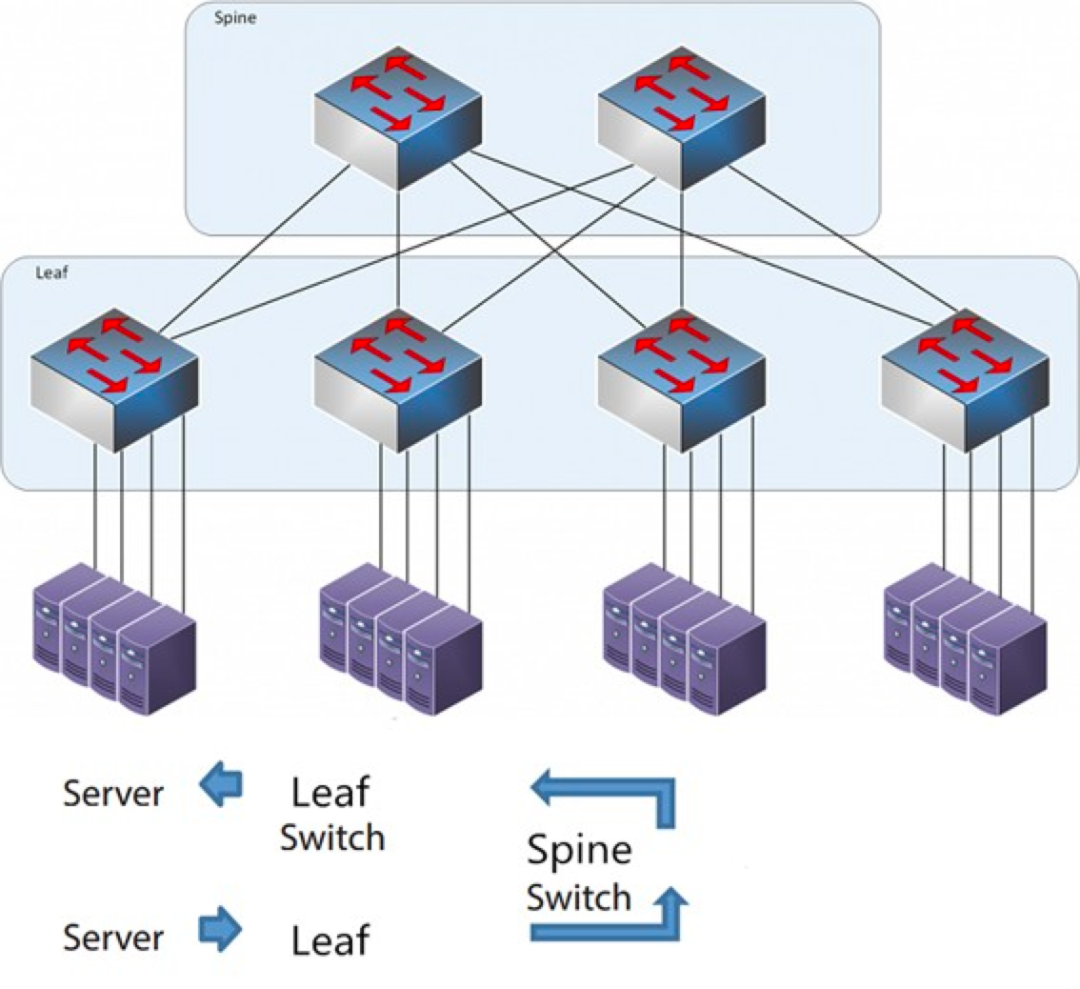
L'architecture épine-feuille
Chaque interrupteur de feuille est connecté à tous les interrupteurs de crête, qui ne sont pas directement connectés entre eux, formant ainsi une topologie maillée complète.
Dans une architecture spine-and-leaf, une connexion entre deux serveurs transite par le même nombre de périphériques (Serveur → Leaf → Commutateur Spine → Commutateur Leaf → Serveur), ce qui garantit une latence prévisible. En effet, un paquet ne doit traverser qu'un seul commutateur Spine et un seul commutateur Leaf pour atteindre sa destination.
Comment fonctionne Spine-Leaf ?
Commutateur Leaf : Il est équivalent au commutateur d'accès dans l'architecture traditionnelle à trois niveaux et se connecte directement au serveur physique en tant que commutateur TOR (Top Of Rack). La différence avec le commutateur d'accès réside dans le fait que le point de démarcation des réseaux L2/L3 se situe désormais sur le commutateur Leaf. Ce dernier se trouve au-dessus du réseau de couche 3 et en dessous du domaine de diffusion L2 indépendant, ce qui résout le problème de la surcharge (BUM) des grands réseaux de couche 2. Si deux serveurs Leaf doivent communiquer, ils doivent utiliser le routage L3 et acheminer le trafic via un commutateur Spine.
Commutateur Spine : Équivalent à un commutateur central. La technologie ECMP (Equal Cost Multi Path) permet de sélectionner dynamiquement plusieurs chemins entre les commutateurs Spine et Leaf. La différence réside dans le fait que le Spine fournit désormais un réseau de routage L3 résilient au commutateur Leaf, permettant ainsi au trafic nord-sud du centre de données d'être acheminé depuis le commutateur Spine plutôt que directement. Le trafic nord-sud peut être acheminé depuis le commutateur de périphérie, parallèlement au commutateur Leaf, vers le routeur WAN.
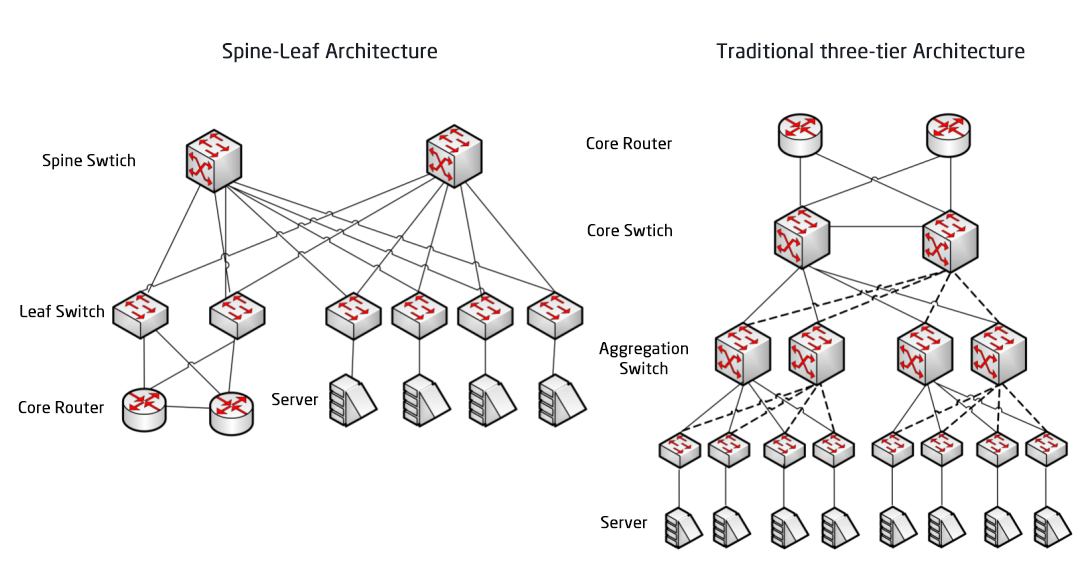
Comparaison entre l'architecture réseau Spine/Leaf et l'architecture réseau traditionnelle à trois couches
Avantages de la feuille épineuse
Plat:Une architecture plate raccourcit le chemin de communication entre les serveurs, ce qui réduit la latence et peut améliorer considérablement les performances des applications et des services.
Bonne évolutivité :Lorsque la bande passante est insuffisante, l'augmentation du nombre de commutateurs de crête permet de l'étendre horizontalement. Lorsque le nombre de serveurs augmente, on peut ajouter des commutateurs de feuille si la densité de ports est insuffisante.
Réduction des coûts : trafic nord-sud, sortant des nœuds feuilles ou des nœuds de crête. Flux est-ouest réparti sur plusieurs chemins. Ainsi, le réseau feuille-crête peut utiliser des commutateurs à configuration fixe, évitant le recours à des commutateurs modulaires onéreux et permettant ainsi une réduction des coûts.
Faible latence et prévention de la congestion :Dans un réseau Leaf Ridge, les flux de données effectuent le même nombre de sauts, quelle que soit la source ou la destination. Deux serveurs quelconques sont accessibles en trois sauts (Leaf → Spine → Leaf). Ceci établit un chemin de trafic plus direct, ce qui améliore les performances et réduit les goulots d'étranglement.
Haute sécurité et disponibilité :Le protocole STP est utilisé dans l'architecture réseau traditionnelle à trois niveaux. Lorsqu'un équipement tombe en panne, il effectue une reconvergence, ce qui affecte les performances du réseau, voire peut entraîner une panne complète. Dans l'architecture leaf-ridge, en cas de panne d'un équipement, la reconvergence n'est pas nécessaire et le trafic continue de transiter par d'autres chemins. La connectivité du réseau n'est pas affectée et la bande passante est seulement réduite d'un seul chemin, avec un impact minime sur les performances.
L'équilibrage de charge via ECMP est parfaitement adapté aux environnements utilisant des plateformes de gestion de réseau centralisées telles que les SDN. Les SDN permettent de simplifier la configuration, la gestion et le réacheminement du trafic en cas de blocage ou de panne de liaison, ce qui rend la topologie maillée complète à équilibrage de charge intelligent relativement simple à configurer et à gérer.
Cependant, l'architecture Spine-Leaf présente certaines limitations :
L'un des inconvénients est que le nombre de commutateurs augmente la taille du réseau. Le centre de données d'une architecture réseau Leaf Ridge doit augmenter le nombre de commutateurs et d'équipements réseau proportionnellement au nombre de clients. À mesure que le nombre d'hôtes augmente, un grand nombre de commutateurs Leaf sont nécessaires pour la liaison montante avec le commutateur Ridge.
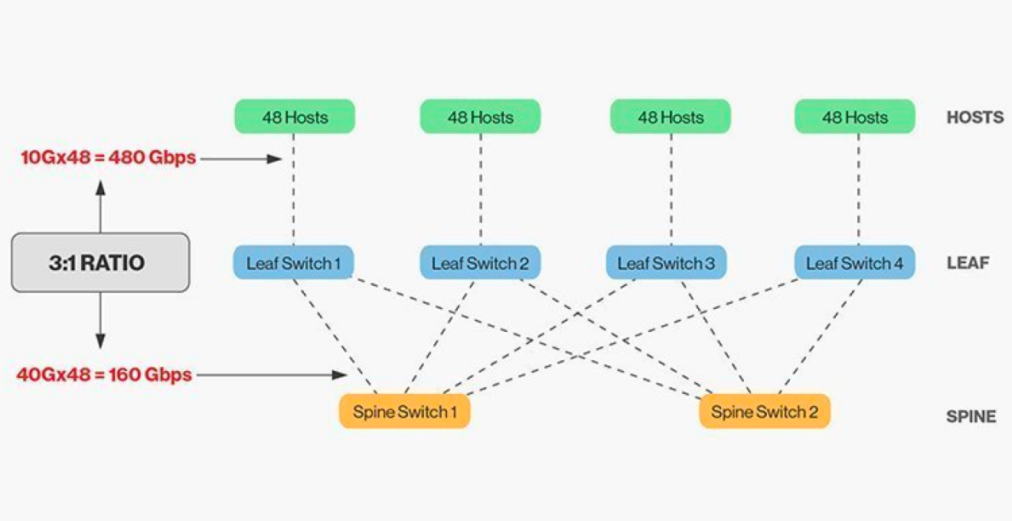
L'interconnexion directe des commutateurs de crête et de feuille nécessite une adaptation, et en général, le rapport de bande passante raisonnable entre les commutateurs de feuille et de crête ne peut pas dépasser 3:1.
Par exemple, un commutateur de périphérie (leaf) compte 48 clients à 10 Gbit/s, pour une capacité totale de 480 Gbit/s. Si les quatre ports de liaison montante 40G de chaque commutateur de périphérie sont connectés au commutateur central 40G, la capacité de liaison montante sera de 160 Gbit/s. Le ratio est donc de 480:160, soit 3:1. Les liaisons montantes des centres de données sont généralement de 40G ou 100G et peuvent être migrées progressivement de 40G (Nx 40G) à 100G (Nx 100G). Il est important de noter que le débit de la liaison montante doit toujours être supérieur à celui de la liaison descendante afin de ne pas saturer la liaison.
Les réseaux Spine-Leaf imposent également des exigences de câblage spécifiques. Chaque nœud Leaf devant être connecté à chaque commutateur Spine, il est nécessaire de déployer davantage de câbles en cuivre ou en fibre optique. La distance d'interconnexion influe considérablement sur les coûts. Selon la distance entre les commutateurs interconnectés, le nombre de modules optiques haut de gamme requis par l'architecture Spine-Leaf est des dizaines de fois supérieur à celui de l'architecture traditionnelle à trois niveaux, ce qui augmente le coût global de déploiement. Toutefois, cette situation a favorisé la croissance du marché des modules optiques, notamment pour les modules à haut débit tels que les modules 100G et 400G.
Date de publication : 26 janvier 2026



